Summary of Chapter 14 – Bivariate Continuous data (Part 3 of 4)
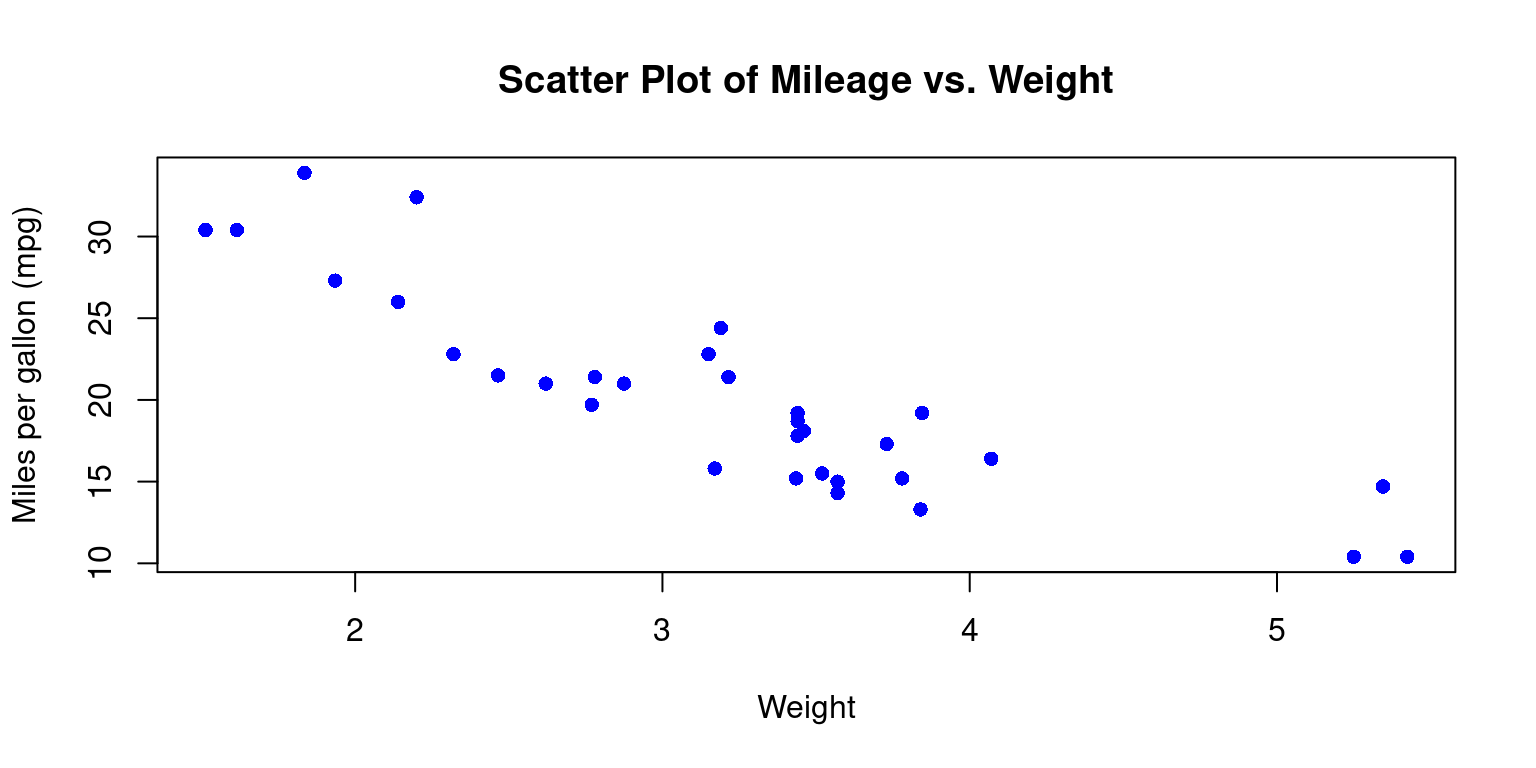
In this chapter, we explore the analysis of relationships between continuous variables. We begin by preparing a sample dataset and converting it to a structured format. As we move forward, we emphasize the importance of visual tools like scatter plots for understanding correlations and patterns between variables. These visual tools can reveal underlying trends, groupings, anomalies, and influential data points.
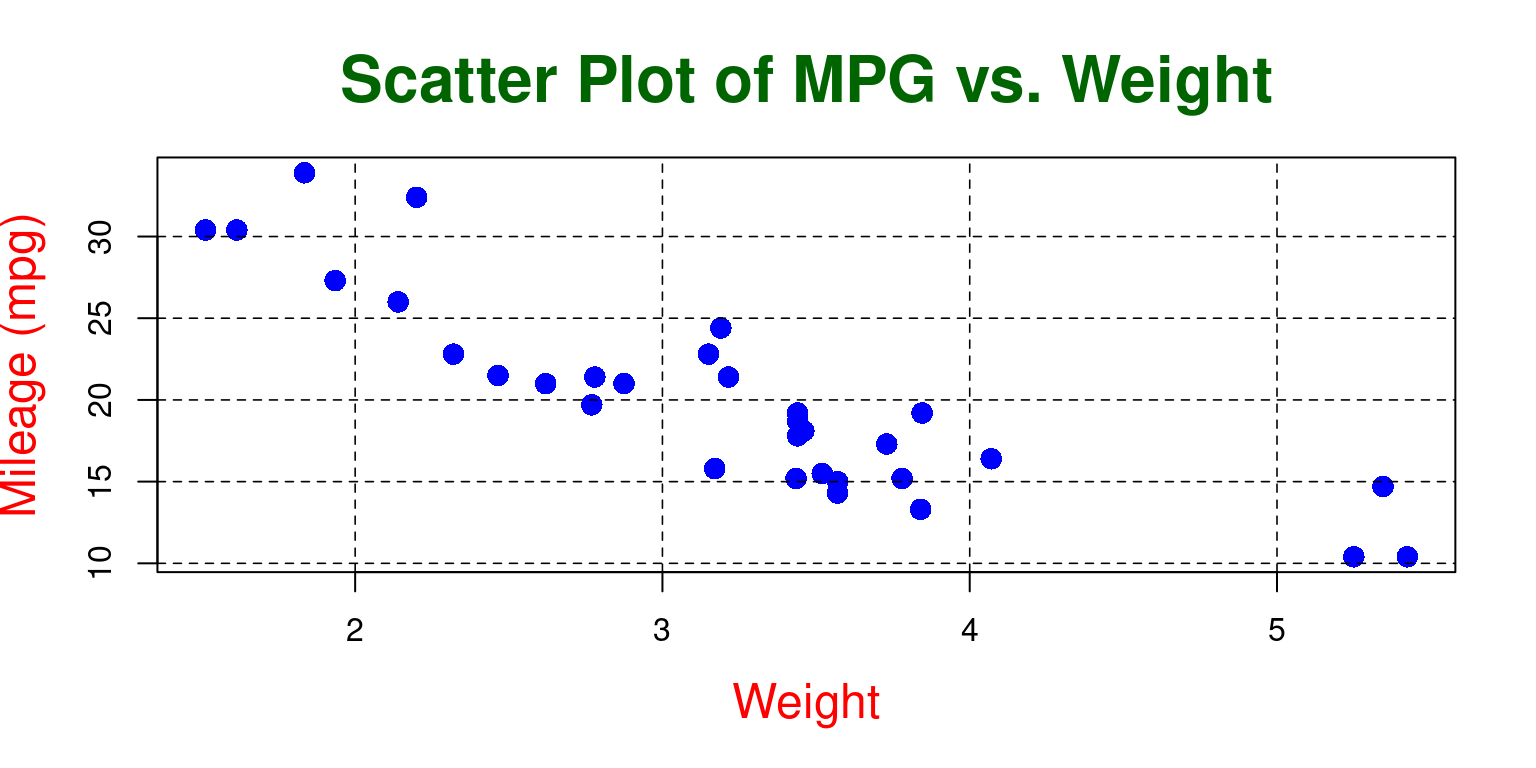
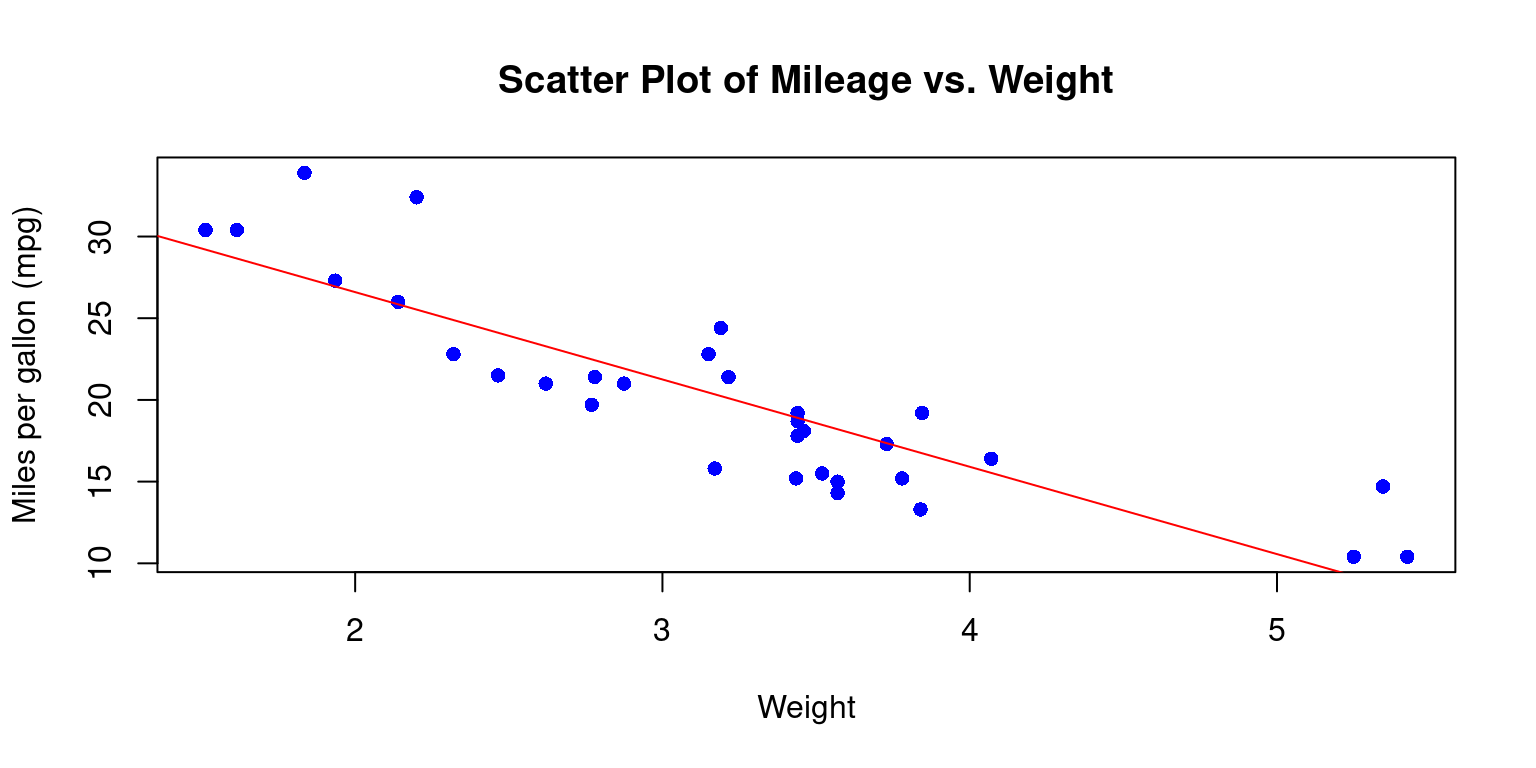
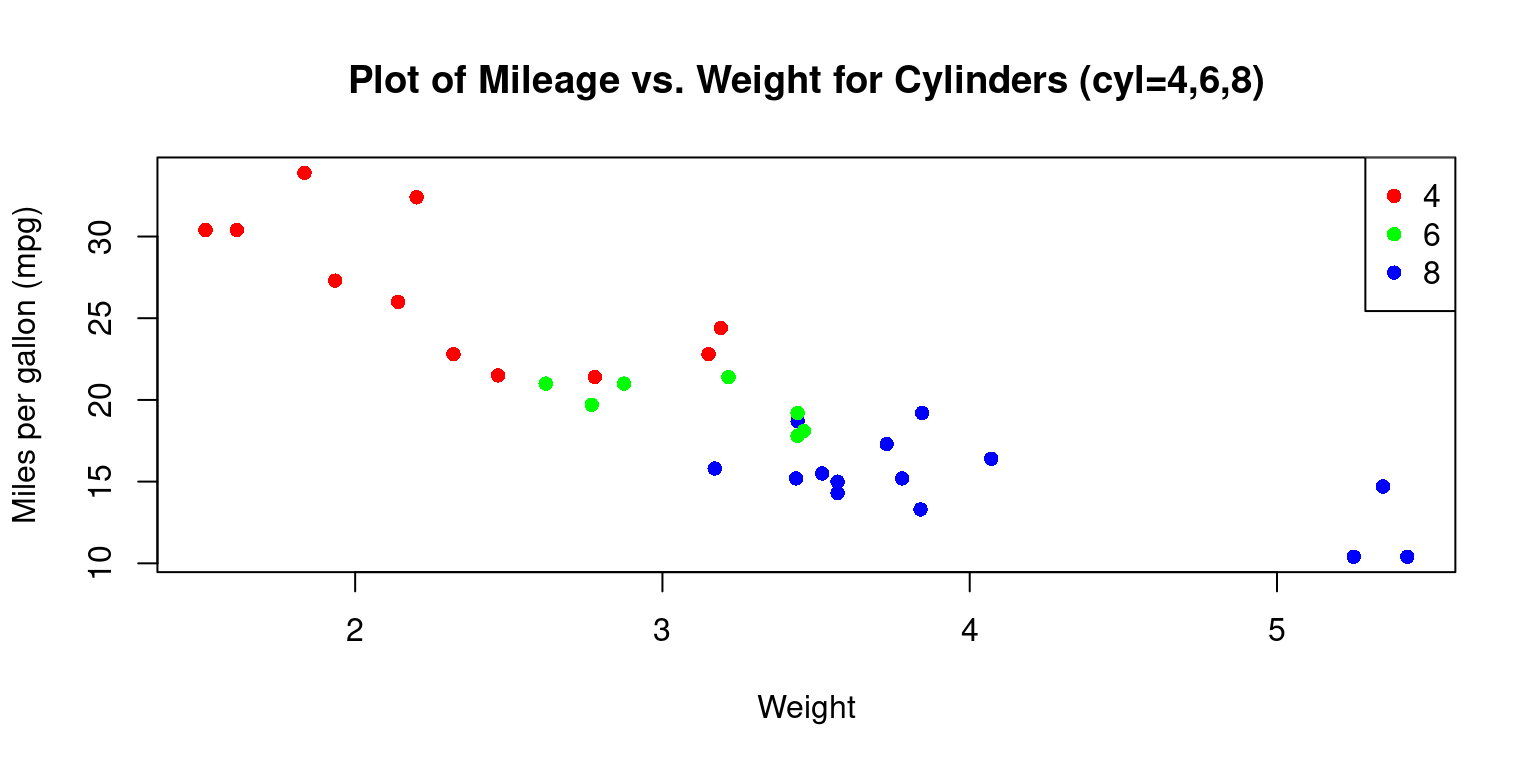
Using practical examples, we demonstrate how to create and customize these visualizations for clearer insights. Additionally, we introduce methods for enhancing scatter plots, including adding trend lines. The chapter also touches on the visualization of interactions between multiple variables, including the integration of categorical data, by means of color differentiation.
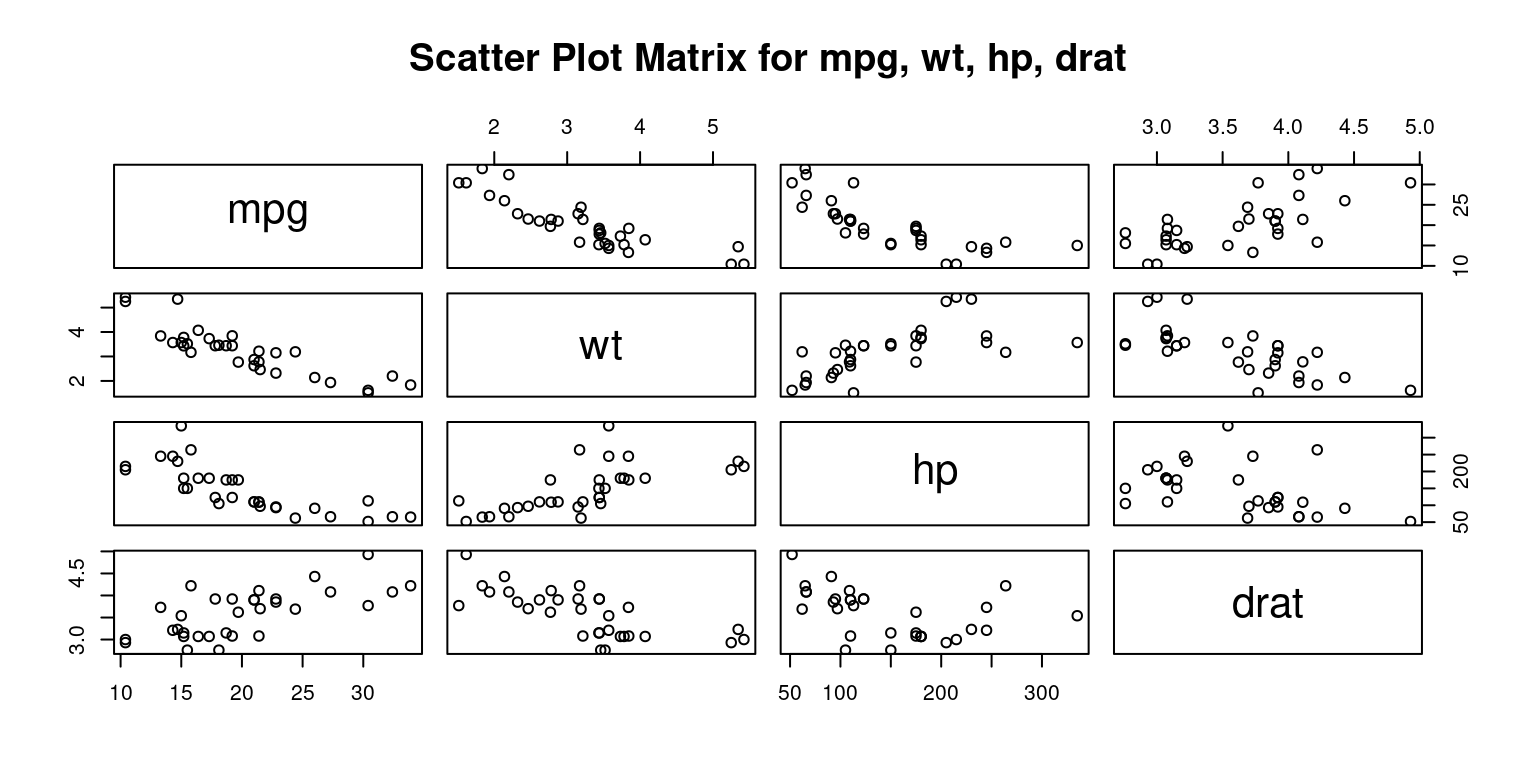
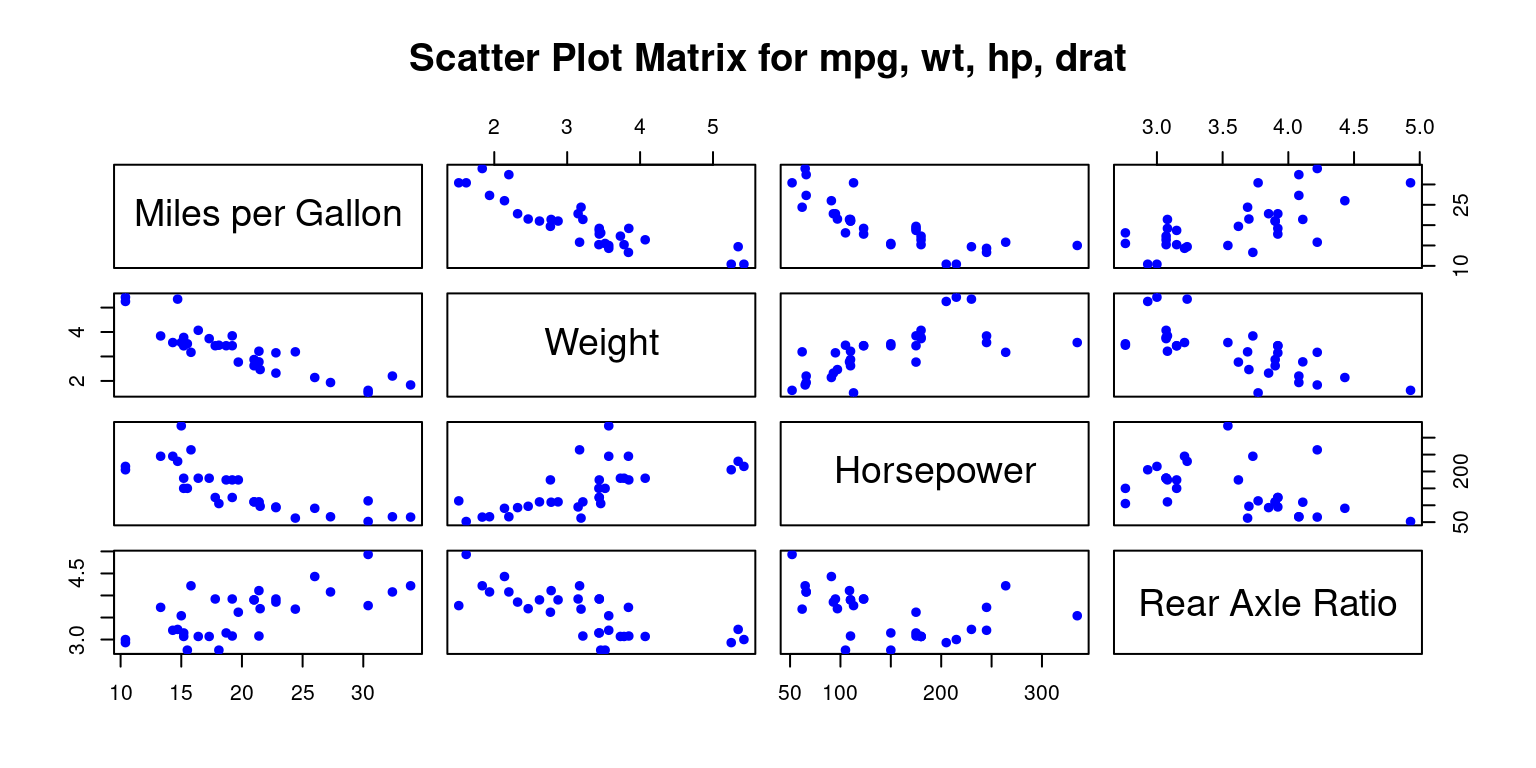
Transitioning from scatter plots, we explore the concept of a scatter plot matrix, or SPLOM. This tool is instrumental in showcasing pairwise relationships between a set of variables in a matrix format. Scatter plot matrices are incredibly helpful when navigating multivariate datasets, allowing quick visual recognition of potential correlations and relationships among variable pairs.
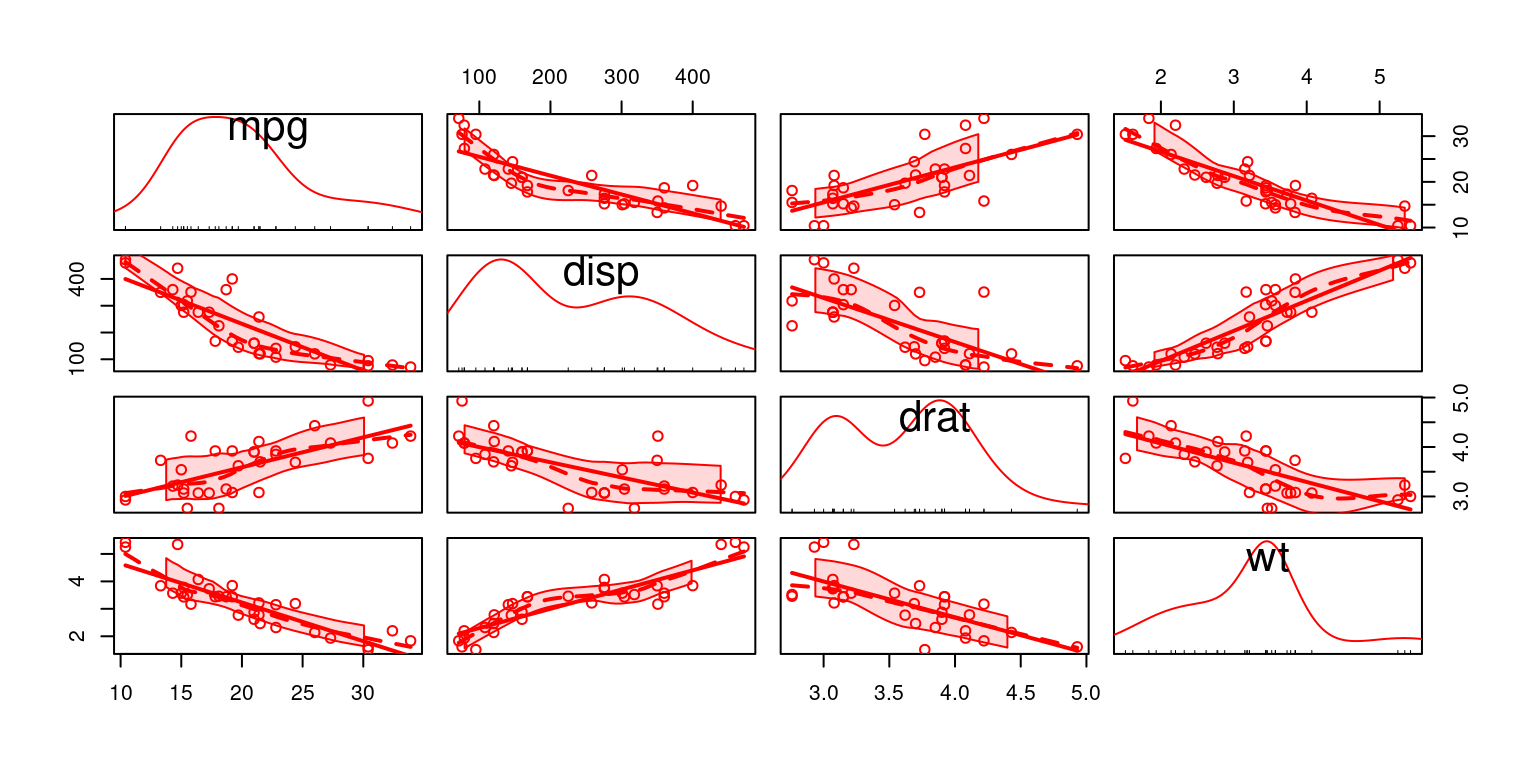
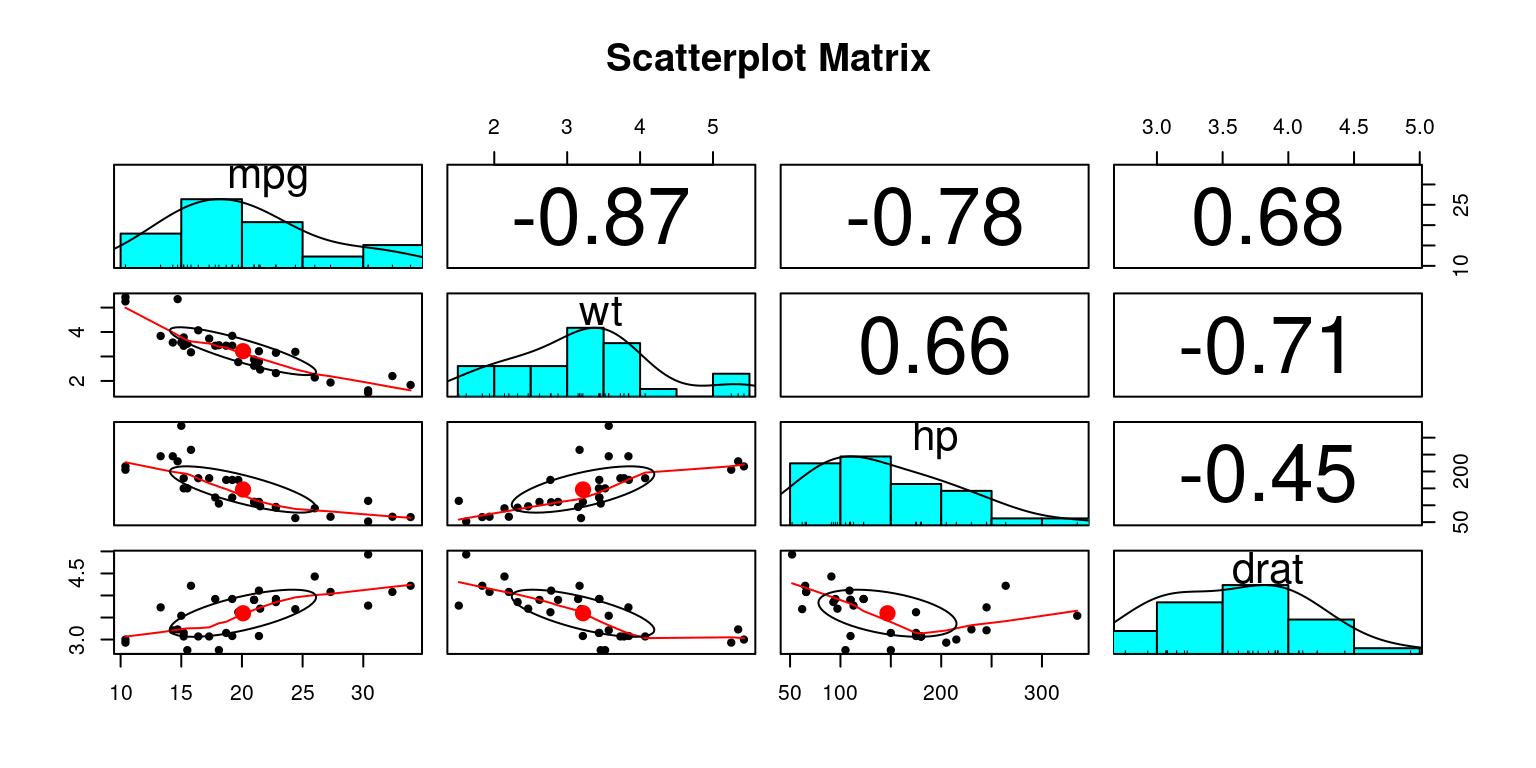
We then demonstrate how to create scatter plot matrices using R functions like pairs(), scatterplotMatrix(), and pairs.panels(). Each method offers a different visual experience and comes with its unique set of features. For example, using pairs.panels() from the psych package, the matrix not only contains scatter plots but also histograms on the diagonal, correlation coefficients, and other enlightening statistical visualizations.
Overall, this chapter equips us with the knowledge to visualize and analyze bivariate continuous data effectively, aiding in more profound data interpretation and insights.
References
Basic R Programming:
[1] Chambers, J. M. (2008). Software for Data Analysis: Programming with R (Vol. 2, No. 1). Springer, New York.
Crawley, M. J. (2012). The R Book. John Wiley & Sons.
Gardener, M. (2012). Beginning R: The Statistical Programming Language. John Wiley & Sons.
Grolemund, G. (2014). Hands-On Programming with R: Write Your Own Functions and Simulations. O’Reilly Media, Inc.
Kabacoff, R. (2022). R in Action: Data Analysis and Graphics with R and Tidyverse. Simon and Schuster.
Peng, R. D. (2016). R Programming for Data Science (pp. 86-181). Leanpub, Victoria, BC, Canada.
R Core Team. (2020). R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria. Retrieved from https://www.R-project.org/.
Tippmann, S. (2015). Programming Tools: Adventures with R. Nature, 517(7532), 109-110.
Wickham, H., Çetinkaya-Rundel, M., & Grolemund, G. (2023). R for Data Science. O’Reilly Media, Inc.
Statistics Using R:
[2] Braun, W. J., & Murdoch, D. J. (2021). A First Course in Statistical Programming with R. Cambridge University Press.
Cohen, Y., & Cohen, J. Y. (2008). Statistics and Data with R: An Applied Approach Through Examples. John Wiley & Sons.
Dalgaard, P. (2008). Introductory Statistics with R. Springer.
Davies, T. M. (2016). The Book of R: A First Course in Programming and Statistics. No Starch Press.
Everitt, B. S., & Hothorn, T. (2014). A Handbook of Statistical Analyses Using R. Chapman and Hall/CRC.
Field, A., Miles, J., & Field, Z. (2012). Discovering Statistics Using R. Sage Publications.
Fox, J., & Weisberg, S. (2018). An R Companion to Applied Regression. Sage Publications.
Hyndman, R. J., & Fan, Y. (1996). Sample Quantiles in Statistical Packages. The American Statistician, 50(4), 361-365.
Matloff, N. (2011). The Art of R Programming: A Tour of Statistical Software Design. No Starch Press.
R Core Team. (2020). R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria. Retrieved from https://www.R-project.org/.
Schumacker, R. E. (2014). Learning Statistics Using R. Sage Publications.
Schumacker, R., & Tomek, S. (2013). Understanding Statistics Using R. Springer Science & Business Media.
Regression:
[3] Fox, J., & Weisberg, S. (2011). An R Companion to Applied Regression (2nd ed.). Sage, Thousand Oaks, CA.
car:
[4] Fox, J., Weisberg, S., Adler, D., Bates, D., Baud-Bovy, G., Ellison, S., Heiberger, R., et al. (2012). Package ‘car’. R Foundation for Statistical Computing, Vienna.
psych:
[5] Revelle, W. (2020). psych: Procedures for Psychological, Psychometric, and Personality Research. Northwestern University, Evanston, Illinois. R Package Version 2.0.12. Retrieved from https://CRAN.R-project.org/package=psych.
GGally:
[6] Schloerke, B., Crowley, J., & Cook, D. (2018). Package ‘GGally’: Extension to ‘ggplot2’.